What’s an MVUE?
All this information is from personal reading. Please let me know if you spot any mistakes. I’m still learning myself!
You’ve probably used an MVUE if you’ve done an exposure monitoring program review or used IHStats. But do you know what it actually is? Sort of? Kind of? Me neither. I did some homework so you don’t have to. Some might describe it as “like the mean, but better” but as we will see this is not necessarily true….
The clues are all in the name “Minimum Variance Unbiased Estimator”. By breaking it down back to front, it turns out to be a pretty simple concept.
Estimator
The three big Es in statistics are ‘Estimand’, ‘Estimator’ and ‘Estimate’.
The estimand is the question we are curious about - what is the standard deviation of test scores among hygienists taking the CIH exam?
The estimator is the method used to answer the estimand - the sample standard deviation of 20 randomly selected examinees.
The estimate is our answer calculated from the estimator to answer the question posed by the estimand - say 15 points.
An estimand can have multiple relevant estimators, and an estimator can give an infinite number of estimate; that is, if you randomly select a different set of 20 examinees, you estimate might be 12.5. Notice two things here. Firstly, an MVUE is a method (or equation) and not a number (which would be the estimate). Secondly, while “MVUE” is often used interchangeably with the arithmetic mean, it could be an estimator for any parameter.
Unbiased
An unbiased estimator is one that is just as likely to overestimate the true parameter value as it is to underestimate it. In other words, the expected value of the estimator IS the parameter value. At first this may seem confusing as the parameter is usually unknowable. But you can prove an estimator mathematically^, and we will see it through simulation. In contrast, a biased estimator will, on average, over- or underestimate the parameter value.
Minimum Variance
If you repeatedly sample a set of measurements, you will get range of estimates. Obviously an estimator that is more consistent (smaller range) is preferable.
So an MVUE is an estimator with the most consistent estimate and is unbiased. If there is an unbiased estimator, there must be an MVUE. An MVUE is always unique. A biased estimator can have less variance than an MVUE.
The Minimum Variance Unbiased Estimator of the Arithmetic Mean
There are several estimators of the estimand: the arithmetic mean (AM) of a lognormally distributed data.
The sample AM is the most simple - divide the sum of observations by the number of observations.

n = number of samples, xi = observations
2. The true AM is the exponent of the position parameter (mu) + half the shape parameter (sigma^2). We can estimate these parameters with the mean and standard deviation of the logged observations. I’ll call this the MLE AM**.

mu hat y = mean of logged observations, sigma hat y = variance of logged observations
3. Lastly, the MVUE of the AM. It’s what we all came to see! Unfortunately, it’s quite complex. It involves a power series - an infinite sum of smaller and smaller terms. Thankfully it’s only necessary to calculate the first 5 or 6 terms before you get a really good approximation.
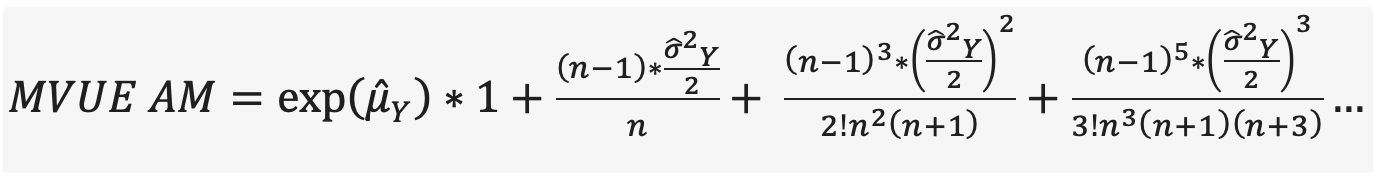
Take a moment to look at the equations first.
Compare the MLE and MVUE. They are both the related to mean and half the variance of the logged data. One difference is that either the variance term is added before or after exponentiation. Perhaps you can guess what effect this might have on the estimates.
Simulation
I wrote code to sample 6 observations from the same lognormal distribution 100,000 times. For each sample, the code calculated the sample, MLE, and MVUE AM. The 100,000 estimates of the 3 means where then plotted. The actual AM from the underlying distribution is shown by the black line. I then repeated this for 12, 30, and 1000 observations.




The first thing I noticed is just how wide each of the three estimates were. This is expected with such a small sample size (6). But it should give us pause when considering the typical sample sizes in hygiene.
Secondly, while you may be able spot differences, the estimators are not extraordinarily different; particularly given how varied each of them are with small sample sizes.
Thirdly, while all three estimators are highly skewed at low sample sizes, they slowly become more and more normally distributed. I think this is the central limit thereom coming into effect… really cool, right?
Fourthly, the MLE and MVUE AM converge as sample size goes to infinity. For any maths nerds, take another look at the equations and see why this might make sense.
Results
The simulation matches the maths!
Here’s what I found:
The MLE AM is slightly positively biased.
The sample AM and MVUE AM are unbiased (the sims say very, very small biased but that’s probably just random variation).
Of the unbiased estimates, the MVUE AM had less variance than the sample AM but not by much.
What surprised me was that the MLE AM had more variance than the MVUE AM, which I had read about in a couple statistics textbooks and papers. My simulations could be wrong though….
So, is there an objective best here? The Mean Squared Error (MSE) is one way to rank estimators. MSE = variance + bias ^2. In this case, the MVUE AM comes out on top as the best estimator.
BAM!
So yes, the MVUE AM is “the mean but better”. But now you know there is a little more to it than that!
^Well… I can’t do it mathematically, but apparently it can be done :D
**Maximum likelihood estimator - I read someone refer to this as the MLE, but I’m not sure it actually is. I use this name regardless for differentiation. Sorry!